Scraping binance futures funding rate data using Python and proxies

Jonny Bravo
-Scraping Binance Futures funding rate data in Python
In this tutorial, we will explore how to scrape public binance perpetual funding rate data and then exploring how to scale this using rotating proxies.
Step 1: Inspect the Website
The first step in web scraping is to inspect the website that you want to scrape. In this case, we want to scrape the funding history page for perpetual futures contracts on Binance.
If you navigate to the website, you'll notice that the URL doesn't contain any symbol data, and the page appears to load the data dynamically.
Step 2: Check AJAX Requests
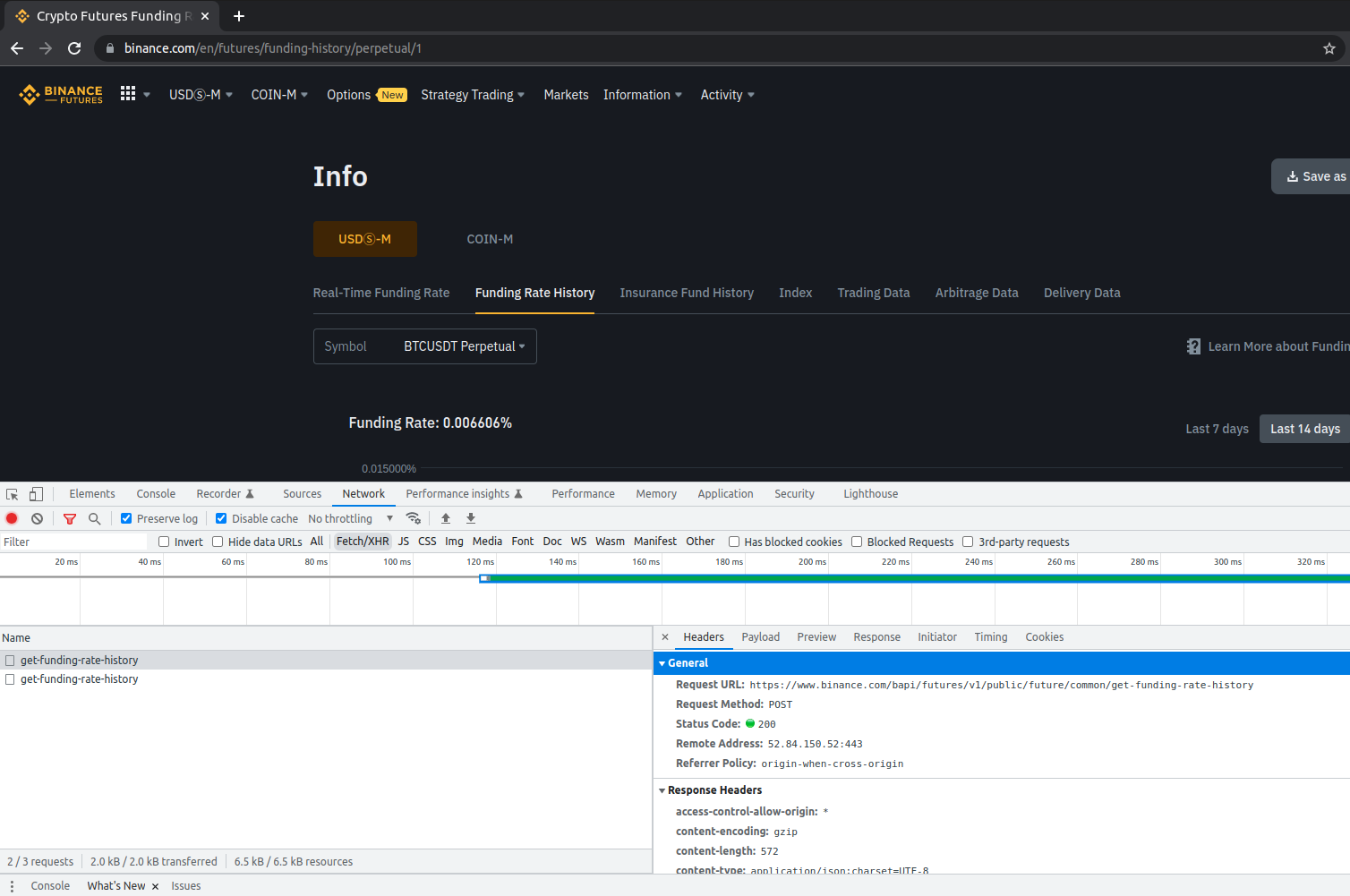
To determine how the data is loaded, we need to check the AJAX requests being made by the website. To do this, we can use the Google Chrome Developer Console.
Open the website in Google Chrome, right-click anywhere on the page, and select "Inspect". This will open the developer console.
Click on the "Network" tab in the developer console. Then, click on the "Fetch/XHR" filter to only show AJAX requests.
Now, refresh the page. You'll notice that several AJAX requests are made. We're interested in the request that loads the funding rate history data.
Click on each request and check the "Preview" and "Response" tabs until you find the request that contains the funding rate history data. In this case, we can see that the data is loaded using a POST request to the URL:
https://www.binance.com/bapi/futures/v1/public/future/common/get-funding-rate-history
Step 3: Check the Payload
Now that we've identified the correct request, we need to check the payload that it sends. To do this, click on the request and go to the "Headers" tab. Scroll down to the "Request Payload" section. In this case, we can see that the payload is a JSON object that contains the symbol, page number, and number of rows.
Here's an example payload:
{ "symbol": "BTCUSDT", "page": 1, "rows": 20 }
This payload specifies the symbol we're interested in (BTCUSDT), the page number (1), and the number of rows to retrieve (20).
Step 4: Python implementation
Below contains the python function that takes in a symbol and start/end page as arguments.
from datetime import datetime import requests BASE_FUNDING_URL = f"https://www.binance.com/bapi/futures/v1/public/future/common/get-funding-rate-history" BASE_HEADERS = { "user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36", "sec-ch-ua-platform": '"Windows"' } def fetch_binance_funding_rates(symbol: str, start_page: int = 1, end_page: int = None): all_data = [] # Create a list to collect all our data while we paginate the URL last_timestamp: datetime = None # In order to prevent us from exceeding the maximum number of pages # Loop over pages in the start / end page ranges provided to the function. for page in range(start_page, (end_page or 9999) + 1): # Send a POST request to binance futures api to fetch the data response = requests.post( BASE_FUNDING_URL, headers=BASE_HEADERS, json={ "symbol": symbol, "page": page, "rows": 100 } ) # If the status code comes back with success (i.e. 200), then we check if we've navigated the same page again. # If so we stop the loop. Otherwise, we add it to the list. if response.status_code == 200: data = response.json()["data"] timestamp = datetime.fromtimestamp(data[-1]['calcTime'] / 1e3) if last_timestamp is not None and timestamp == last_timestamp: break last_timestamp = timestamp all_data.extend(data) else: print(f"Error: Could not retrieve data for page {page} / {response.content}") return all_data if __name__ == '__main__': fetch_binance_funding_rates(symbol='BTCUSDT', start_page=1, end_page=2)
Step 5: Scaling with Proxies
The issue with the python code in the previous step is that we risk getting rate limited or our IP being completely banned by Binance.
A possible solution to this issue is to use Rotating Proxies. This is a service that will mask your IP address by routing your request to a pool of proxies that will handle send the request and return the response back to you. After every request, the IP is changed, allowing you to collect the data without any limitations.
More information can be found here regarding rotating proxies
Intergrating rotating proxies
We need to now isolate the part of the python code that will actually send the request to Binance via the proxies. The reason for this is that we cannot guarantee that each requests routed via the rotating proxies will be successful and it will allow us to easily retry that part specifically.
We will be using the retry python library to allow us to retry modules by using a simple function decorator.
Here is the updated code.
from datetime import datetime import requests from retry import retry BASE_FUNDING_URL = f"https://www.binance.com/bapi/futures/v1/public/future/common/get-funding-rate-history" BASE_HEADERS = { "user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36", "sec-ch-ua-platform": '"Windows"' } @retry(tries=8) def post(url: str, headers=None, payload=None) -> requests.Response: r = requests.post( url, headers=headers, json=payload, timeout=8, proxies={ 'http': 'http://USERNAME:PASSWORD@proxy.fluxy.io:3128', 'https': 'http://USERNAME:PASSWORD@proxy.fluxy.io:3128' } ) # Raise any failed responses in order to retry r.raise_for_status() return r def fetch_binance_funding_rates(symbol: str, start_page: int = 1, end_page: int = None): all_data = [] # Create a list to collect all our data while we paginate the URL last_timestamp: datetime = None # In order to prevent us from exceeding the maximum number of pages # Loop over pages in the start / end page ranges provided to the function. for page in range(start_page, (end_page or 9999) + 1): # Send a POST request to binance futures api to fetch the data data = post( url=BASE_FUNDING_URL, headers=BASE_HEADERS, payload={ "symbol": symbol, "page": page, "rows": 100 } ).json()['data'] # If the status code comes back with success (i.e. 200), then we check if we've navigated the same page again. # If so we stop the loop. Otherwise, we add it to the list. timestamp = datetime.fromtimestamp(data[-1]['calcTime'] / 1e3) if last_timestamp is not None and timestamp == last_timestamp: break last_timestamp = timestamp all_data.extend(data) return all_data if __name__ == '__main__': fetch_binance_funding_rates(symbol='BTCUSDT', start_page=1, end_page=2)